

バッチファイルで
画像ファイル内のテキストを・・・

抽出できます!
※OCRできます。
※精度はそこそこです。
バッチファイルから
・無料のOCRエンジン「tesseract-ocr」
を実行することで実現します!
※「tesseract-ocr」のインストールが必要です。
tesseract-ocrのダウンロードとインストール
以下の記事の「tesseract-ocrのダウンロード」と「tesseract-ocrのインストール」をご確認ください。

コード
ここでは例として
・デスクトップ配下の画像ファイル「sample_gazou.png」から
・テキストを抽出
します。
※テキストファイルを出力します。
@echo off
rem Tesseract OCRの実行ファイル
set tesseractOcrExe="C:\Program Files\Tesseract-OCR\tesseract.exe"
rem 画像ファイル
set imageFile=C:\Users\user\Desktop\sample_gazou.png
rem 出力ファイル名
set outputFileName=sampleOcr
rem 出力フォルダ ※末尾に「\」を付ける
set outputFolder=C:\Users\user\Desktop\output\
rem OCR実行
%tesseractOcrExe% %imageFile% %outputFolder%%outputFileName% -l jpn
rem 実行結果を確認
if %errorlevel% == 0 (
echo 正常終了しました。戻り値:%errorlevel%
) else (
echo 異常終了しました。戻り値:%errorlevel%
)
echo.
pause
exit実行結果
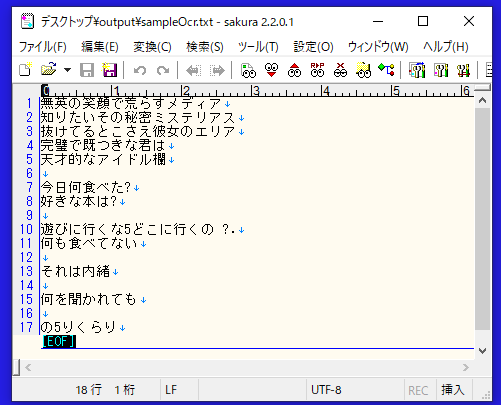
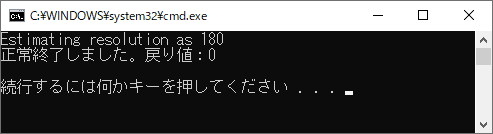
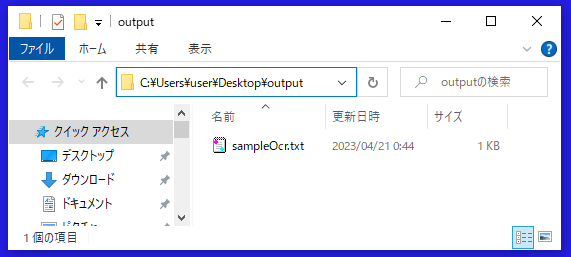
画像ファイル内のテキストを抽出できました。
※テキストファイルを出力できました。
参考
OCRエンジン「tesseract-ocr」はHPやGoogle等により開発されました。
詳細は以下をご確認ください。